In this post working of the HDFS components Namenode, Datanode and Secondary Namenode are explained in detail.
Namenode in Hadoop
HDFS works on a master/slave architecture. In HDFS cluster Namenode is the master and the centerpiece of the HDFS file system.
Namenode manages the file system namespace. It keeps the directory tree of all files in the file system and metadata about files and directories.
Metadata information stored about the file consists of– full file name, last access time, last modification time, access permissions, blocks file is divided into, replication level of the file etc.
Metadata information stored about the directory consists of modification time, access permissions etc.
This metadata information is stored on the disk for persistence storage in form of two files-
- fsimage– Contains the snapshot of the file system metadata and used by Namenode when it is started.
- edit log– Any change made to the filesystem, after the Namenode is started, is recorded in edit logs.
Apart from persisting it on the disk, Namenode also holds the metadata information in main memory for faster processing of requests. Information about the datanodes that have stored the blocks for any given file is also kept in main memory.
Any client application that needs to process any existing file or want to copy a new file has to talk to Namenode. The Namenode returns a list of Datanodes where blocks of existing files are residing or blocks of a new file can be written and replicated.
DataNode in Hadoop
Though Namenode in Hadoop acts as an arbitrator and repository for all metadata but it doesn’t store actual data of the file. HDFS is designed in such a way that user data never flows through the NameNode. Actual data of the file is stored in Datanodes in Hadoop cluster.
Datanodes store or access the blocks of the file for the client application after Namenode provides the list of Datanodes where blocks have to be stored or from where the blocks have to be read.
To keep Namenode current Datanodes periodically send the information about the blocks they are storing to Namenode.
Secondary Namenode in Hadoop
From its name you may think Secondary Namenode is some kind of back up server which will start acting like a Namenode in case the Namenode fails, but that is not the case. Secondary Namenode can be thought of as an assistant to Namenode that takes some of the work load of the Namenode.
What does Secondary Namenode do
As already mentioned Namenode persists information about file system metadata in two files fsimage and edit logs.
Out of these two files fsimage is consulted to get the metadata information when the Namenode starts. After the Nameode starts all the changes to the namespace are recorded in edit logs. Now that may cause some problems as Namenode is not restarted that often so edit logs may become quite large.
When the Namenode is eventually restarted it has to first consult the fsimage and then apply all the changes recorded in edit logs which means taking more time for namenode to restart.
So the problem is Namenode merges fsimage with edit logs only during startup. That is where Secondary Namenode helps, it can take over the responsibility of merging the fsimage and the edits log files periodically that way edits log size is kept within a limit and Namenode has a merged fsimage file.
The start of the checkpoint process (When Secondary Namenode should start merging process) is controlled by two configuration parameters-
- dfs.namenode.checkpoint.period, set to 1 hour by default, specifies the maximum delay between two consecutive checkpoints, and
- dfs.namenode.checkpoint.txns, set to 1 million by default. Which means start the merging process if one million transactions are recorded in the edit log since the last checkpoint.
Process
- Secondary Namenode gets the latest fsimage and edit logs from Namenode.
- It merges the transactions from edit logs to fsimage to create a new fsimage file.
- Copies the newly created fsimage file back to Namenode.
That way Namenode receives merged fsimage file periodically which reduces the restart time of the Namenode.
You can specify Secondary Namenode using this property- dfs.namenode.secondary.http-address in
hdfs-site.xml.
The communication among Namenode, Datanode and Secondary Namenode in Hadoop can be shown using the following image-
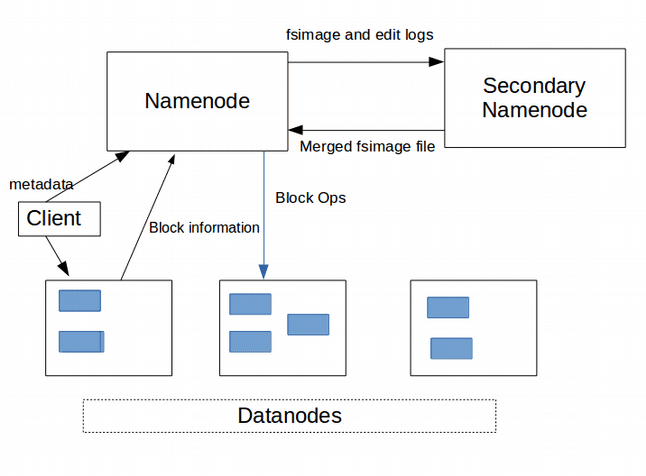
That's all for the topic NameNode, Secondary Namenode and Datanode in HDFS. If something is missing or you have something to share about the topic please write a comment.
You may also like
- Namenode in Safemode
- Hadoop MapReduce Word Count Program
- Frequently Used HDFS Commands With Examples
- How to Read And Write Parquet File in Hadoop
- Java ConcurrentHashMap With Examples
- How to Convert String to int in Java
- Find Length of String Without Using length() Method in Java
- Encapsulation in Python With Examples
No comments:
Post a Comment