In this article we’ll see a Spring Boot Microservices example with Eureka used for service registration and discovering
the service. We’ll have two separate services User and Account developed as Microservices. With two microservices we'll
also see how to call one microservice from another using RestTemplate.
When a large monolith application is split into two or more microservices those microservices may need to interact with
each other. To do that these microservices need to be aware of each others existence and should be able to find each other.
This process is known as service discovery. There is a tool called Eureka created by Netflix that can act
as a discovery server, for that you need to register your microservices with the Eureka server.
So, in this Spring Boot Microservices example we are going to create 3 separate Spring Boot applications
two for the functionality of User and Account and third one for Eureka Server.
Spring Boot application for Eureka Server
First we’ll create a Spring Boot project for configuring Eureka Server, this application acts as a service registry.
Starter you need to add for Eureka Server is spring-cloud-starter-netflix-eureka-server
Maven dependencies – pom.xml
pom.xml with the starter dependencies. Note that Spring Boot version used is 2.3.4.RELEASE and Spring Cloud version is
Hoxton.SR8
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.knpcode</groupId>
<artifactId>springeureka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>EurekaServer</name>
<description>Eureka Server project</description>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Application class
Application class with main method.
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
In the application class apart from @SpringBootApplication annotation another annotation @EnableEurekaServer is also added.
@EnableEurekaServer annotation indicates that we want to run a Eureka Server. By seeing a dependency on
Spring Cloud Eureaka, Spring Boot automatically configures the application as a service registry.
Eureka Server Configuration
In the application.properties put the following.
server.port=8761
eureka.instance.hostname=localhost
eureka.client.register-with-eureka=false
eureka.client.fetch-registry=false
server.port configures the port Eureka Server runs on.
For a stand alone instance we don’t want Eureka Server to be a client too that is why these two entries-
eureka.client.register-with-eureka=false
eureka.client.fetch-registry=false
Running Eureka Server
Eureka server application is ready and you can run the EurekaServerApplication class to start the Eureka Server.
You should get the following messages if every thing runs fine-
2020-03-12 14:53:16.457 INFO 14400 --- [ Thread-10] e.s.EurekaServerInitializerConfiguration : Started Eureka Server
2020-03-12 14:53:16.503 INFO 14400 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8761 (http) with context path ''
2020-03-12 14:53:16.507 INFO 14400 --- [ main] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 8761
2020-03-12 14:53:19.314 INFO 14400 --- [ main] o.n.s.EurekaServerApplication : Started EurekaServerApplication in 30.203 seconds (JVM running for 33.929)
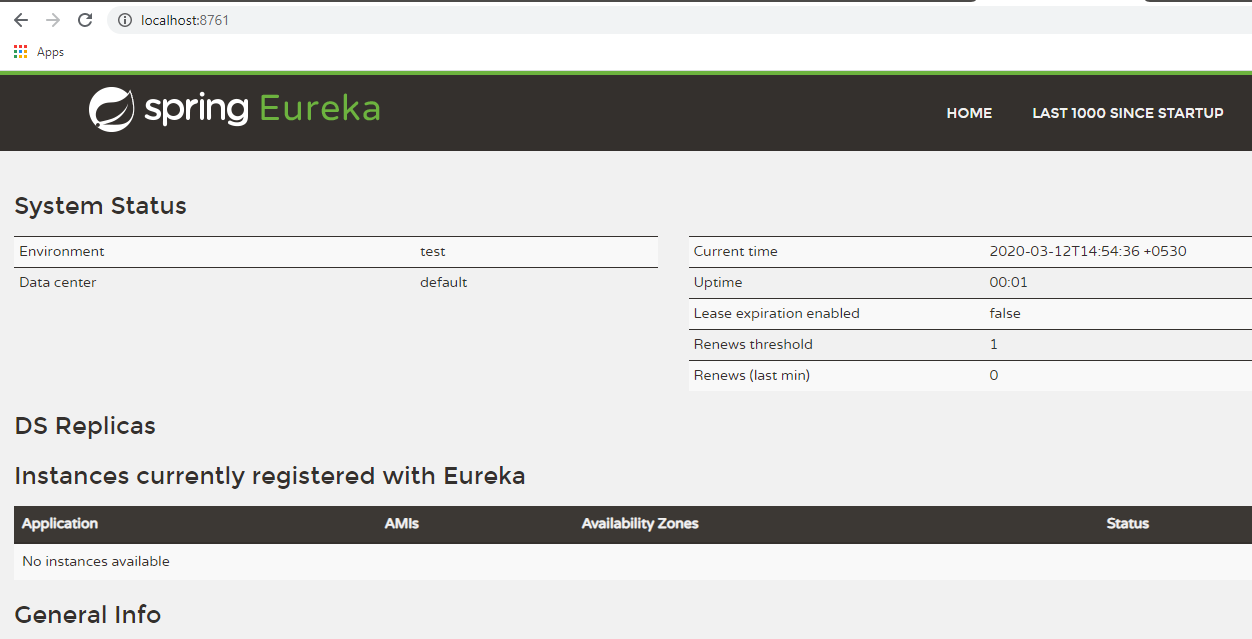
You can see the Eureka Server console by accessing URL- http://localhost:8761/
As you can see currently no instances are registered with Eureka. That’s what is the next task, to create Spring Boot
microservices and register them with Eureka Server.
Spring Boot Account application
Create another Spring Boot project for Account Microservice, starter dependency for eureka client has to be added,
in place of eureka-server, to register this Microservice as Eureka client. All the other dependencies remain same as
used in Eureka Server application.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
Rest Controller class
We’ll add a controller with the functionality to find all the accounts for the passed EmployeeId.
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class AccountController {
@Autowired
private AccountService accountService;
@GetMapping(value="/accounts/{empId}")
public List<Account>getAccountsByEmpId(@PathVariable String empId) {
System.out.println("EmpId------" + empId);
List<Account> empAccountList = accountService.findAccountsByEmpId(empId);
return empAccountList;
}
}
AccountService class
In the AccountService class you can see there is a dummy method to get the Accounts rather than accessing DB in order to
keep the focus on interaction between microservices.
import java.util.ArrayList;
import java.util.List;
import org.springframework.stereotype.Service;
@Service
public class AccountService {
public List<Account> findAccountsByEmpId(String empId){
List<Account> accountList = getAccountList();
List<Account> empAccountList = new ArrayList<>();
for(Account account : accountList) {
if(account.getEmpId().equals(empId))
empAccountList.add(account);
}
return empAccountList;
}
private List<Account> getAccountList(){
List<Account> accountList = new ArrayList<>();
accountList.add(new Account("1", "AC1", "MT"));
accountList.add(new Account("1", "AC2", "IN"));
accountList.add(new Account("2", "AC3", "IN"));
return accountList;
}
}
DTO Class
There is also an Account class that acts as a DTO or a model bean.
public class Account {
private String empId;
private String accountId;
private String branch;
Account(){
}
Account(String empId, String accountId, String branch){
this.empId = empId;
this.accountId = accountId;
this.branch = branch;
}
public String getEmpId() {
return empId;
}
public void setEmpId(String empId) {
this.empId = empId;
}
public String getAccountId() {
return accountId;
}
public void setAccountId(String accountId) {
this.accountId = accountId;
}
public String getBranch() {
return branch;
}
public void setBranch(String branch) {
this.branch = branch;
}
}
Application class
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication
public class SpringBootAccountApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootAccountApplication.class, args);
}
}
Application class is annotated with the @EnableDiscoveryClient (so that this application can be discovered as Eureka client,
you can also use @EnableEurekaClient annotation instead of @EnableDiscoveryClient) along with the @SpringBootApplication
annotation.
Configuration for Eureka Client
Following properties are also to be added to the application.properties file to register Account Microservice as Eureka
client.
eureka.client.service-url.default-zone=http://localhost:8761/eureka
server.port=9000
spring.application.name=account
eureka.client.service-url.default-zone property tells our microservice where to look for Eureka Server.
Using spring.application.name you give a logical name to your microservice.
Server port is configured as 9000 so this Account application runs on port 9000.
Registering Account Microservice as Eureka client
Run the SpringBootAccountApplication class to start this RESTful service. It will automatically be registered as Eureka
client. You can verify that seeing the messages on the console.
2020-03-12 15:23:58.585 INFO 12416 --- [ restartedMain] o.s.c.n.e.s.EurekaServiceRegistry : Registering application ACCOUNT with eureka with status UP
2020-03-12 15:23:58.588 INFO 12416 --- [ restartedMain] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [timestamp=1584006838588, current=UP, previous=STARTING]
2020-03-12 15:23:58.597 INFO 12416 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_ACCOUNT/user:account:9000: registering service...
2020-03-12 15:23:58.940 INFO 12416 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 9000 (http) with context path ''
2020-03-12 15:23:58.945 INFO 12416 --- [ restartedMain] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 9000
2020-03-12 15:23:59.194 INFO 12416 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_ACCOUNT/user:account:9000 - registration status: 204
2020-03-12 15:24:02.128 INFO 12416 --- [ restartedMain] o.n.a.SpringBootAccountApplication : Started SpringBootAccountApplication in 31.85 seconds (JVM running for 35.175)
Verifying Eureka Server
If you refresh the URL for Eureka Server- http://localhost:8761/ now you should see an instance registered. Name of the
instance is same as what was configured as a logical name using the following property.
spring.application.name=account
Spring Boot User application
Another microservice we need to create is the User service so create another project. There again add the same starter
dependency to register this Microservice as Eureka client.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
Rest Controller class
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping(value="/user/{id}")
public List<Account> showEmployees(@PathVariable("id") String id) {
List<Account> accounts = userService.showEmployees(id);
// displaying accounts
for(Account acct : accounts) {
System.out.println(acct.getEmpId());
System.out.println(acct.getAccountId());
System.out.println(acct.getBranch());
}
return accounts;
}
}
UserService Class
In method showEmployees there is a call to the Account microservice to get all the associated accounts for the passed
employee ID.
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.client.RestTemplate;
@Service
public class UserService {
@Autowired
private RestTemplate restTemplate;
public List<Account> showEmployees(@PathVariable("id") String id) {
System.out.println(id);
//List<Account> accounts = new RestTemplate().exchange(
//"http://localhost:9000/accounts/{empId}", HttpMethod.GET, null, new
//ParameterizedTypeReference<List<Account>>(){}, id).getBody();
List<Account> accounts = restTemplate.exchange(
"http://ACCOUNT/accounts/{empId}", HttpMethod.GET, null, new
ParameterizedTypeReference<List<Account>>(){}, id).getBody();
return accounts;
}
}
restTemplate.exchange() is the method used for making remote call to another microservice.
- First argument to restTemplate.exchange() is the URL to the Account microservice- "http://ACCOUNT/accounts/{empId}"
- Second argument specifies that it is a HTTP Get command.
- Third argument specifies the entity (headers and/or body) to write to the request. As we are not passing any request entity so it is null.
- Fourth argument specifies the type of the response.
- Fifth argument specifies the variables to expand in the template. We are passing id there which will replace {empId} in the URL.
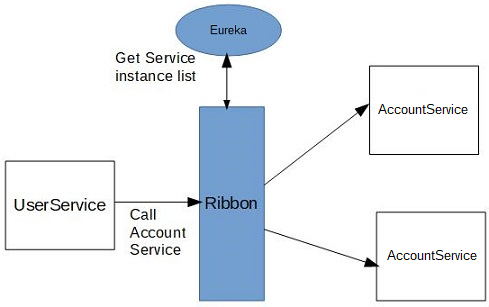
Using Ribbon Load Balancer
In the above method you can see that the URL used for calling Microservice is http://ACCOUNT/accounts/{empId} though you
can also use http://localhost:9000/accounts/{empId} but that hardcodes the location which is not good.
To avoid that hardcoding we are using Netflix's Ribbon service which can be integrated with Eureka.
What we need to do is to mark a RestTemplate bean to be configured to use a LoadBalancerClient, to do that we can create
RestTemplate bean as following.
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class Config {
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}
Once you have this Load balanced restTemplate instance then you can use the logical name of the service, in the URL,
that was used to register it with Eureka. That’s how we are using this URL http://ACCOUNT/accounts/{empId} to access
Account MicroService.
Application class
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication
public class SpringBootUserApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootUserApplication.class, args);
}
}
Configuration for Eureka Client
Following properties are also to be added to the application.properties file to register User Microservice as Eureka client.
eureka.client.service-url.default-zone=http://localhost:8761/eureka
spring.application.name=user
Run the SpringBootUserApplication to start User MicroService. It will automatically be registered as Eureka client. You can
verify that by seeing the messages on the console.
2020-03-12 16:24:00.228 INFO 9844 --- [ restartedMain] o.s.c.n.e.s.EurekaServiceRegistry : Registering application USER with eureka with status UP
2020-03-12 16:24:00.231 INFO 9844 --- [ restartedMain] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [timestamp=1584010440231, current=UP, previous=STARTING]
2020-03-12 16:24:00.240 INFO 9844 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_USER/user:user: registering service...
2020-03-12 16:24:00.402 INFO 9844 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_USER/user:user - registration status: 204
2020-03-12 16:24:00.572 INFO 9844 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2020-03-12 16:24:00.577 INFO 9844 --- [ restartedMain] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 8080
2020-03-12 16:24:03.278 INFO 9844 --- [ restartedMain] com.knpcode.user.SpringBootUserApplication : Started SpringBootUserApplication in 28.889 seconds (JVM running for 33.647)
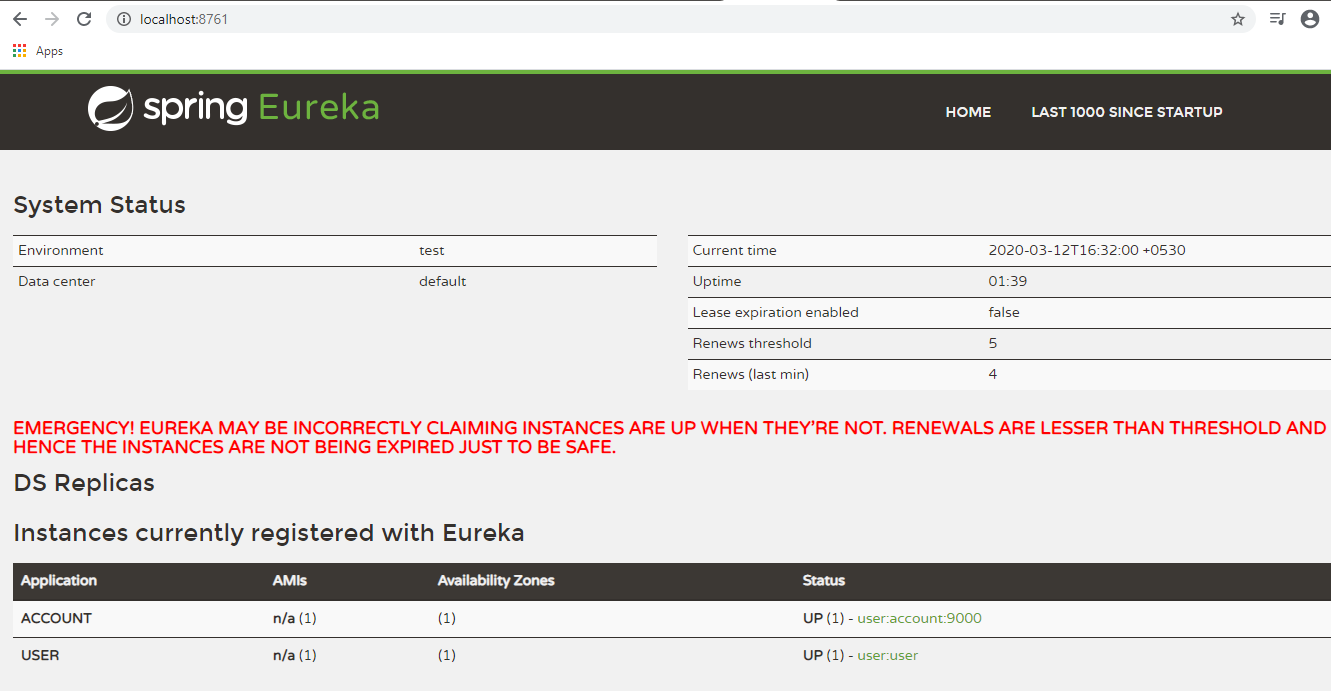
If you refresh the URL for Eureka Server- http://localhost:8761/ you should see both the MicroServices registered as Eureka
clients.
Communication between MicroServices
Now we have two MicroSerivces created and running. Both of the MicroServices are registered with Eureka so these services
can be discovered using Eureka.
Now when you access the URL http://localhost:8080/user/1 it will be serviced by showEmployees() method of the UserController
in SpringBootUser application. From there using restTemplate.exchange() method it communicates with Account service.
The URL (http://ACCOUNT/accounts/{empId}) passed in the exchange method triggers the whole process of load balancing and
discovering the Eureka client as evident from the log messages.
2020-03-12 16:36:37.733 INFO 9844 --- [nio-8080-exec-1] c.netflix.config.ChainedDynamicProperty : Flipping property: ACCOUNT.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
2020-03-12 16:36:37.915 INFO 9844 --- [nio-8080-exec-1] c.n.u.concurrent.ShutdownEnabledTimer : Shutdown hook installed for: NFLoadBalancer-PingTimer-ACCOUNT
2020-03-12 16:36:37.916 INFO 9844 --- [nio-8080-exec-1] c.netflix.loadbalancer.BaseLoadBalancer : Client: ACCOUNT instantiated a LoadBalancer: DynamicServerListLoadBalancer:{NFLoadBalancer:name=ACCOUNT,current list of Servers=[],Load balancer stats=Zone stats: {},Server stats: []}ServerList:null
2020-03-12 16:36:37.963 INFO 9844 --- [nio-8080-exec-1] c.n.l.DynamicServerListLoadBalancer : Using serverListUpdater PollingServerListUpdater
2020-03-12 16:36:38.090 INFO 9844 --- [nio-8080-exec-1] c.netflix.config.ChainedDynamicProperty : Flipping property: ACCOUNT.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
2020-03-12 16:36:38.098 INFO 9844 --- [nio-8080-exec-1] c.n.l.DynamicServerListLoadBalancer : DynamicServerListLoadBalancer for client ACCOUNT initialized: DynamicServerListLoadBalancer:{NFLoadBalancer:name=ACCOUNT,current list of Servers=[user:9000],Load balancer stats=Zone stats: {defaultzone=[Zone:defaultzone; Instance count:1; Active connections count: 0; Circuit breaker tripped count: 0; Active connections per server: 0.0;]
},Server stats: [[Server:user:9000; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Thu Jan 01 05:30:00 IST 1970; First connection made: Thu Jan 01 05:30:00 IST 1970; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0]
]}ServerList:org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList@5820f552
1
AC1
MT
1
AC2
IN
2020-03-12 16:36:38.995 INFO 9844 --- [erListUpdater-0] c.netflix.config.ChainedDynamicProperty : Flipping property: ACCOUNT.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
favicon.ico
2020-03-12 16:38:59.147 INFO 9844 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration
2020-03-12 16:43:59.150 INFO 9844 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration
Download sourcecode- SpringBoot-MicroService-Example
That's all for the topic Spring Boot Microservices Example. If something is missing or you have something
to share about the topic please write a comment.
You may also like