The way Lambda expressions in Java brought functional programming to Java another addition in Java 8, Stream API in Java brought functional approach to processing collections of objects. Using Java Stream API you can create a stream over an object and then you just need to specify what needs to be done not how it has to be done.
For example if you want to count the elements in the stream, you need to specify the source for obtaining a stream and the function to count the elements. Stream API takes care of executing stream pipeline in an optimized way.
List<Integer> myList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
long count = myList.stream().count();
System.out.println("Count of elements in the list- " + count);
In the above example List myList is the data source for the stream and count is the stream operation performed on the stream.
In this Java Stream API tutorial we’ll see how to create streams, types of streams and various stream operation examples. Since the examples use lambda expressions and functional interfaces so make sure that you are familiar with those topics.
Java Stream API – Interfaces and Classes
Java Stream API contains several interfaces and classes which are packaged with in the java.util.stream
package. At the top of the hierarchy is interface BaseStream providing basic functionality for all
the Streams.
BaseStream interface is extended by interfaces- DoubleStream, IntStream, LongStream and Stream. Stream interface is a generic interface which is used for all reference types.
DoubleStream, IntStream and LongStream are primitive specializations of Stream that can store primitive values.
Read more about Primitive Streams in this post- Primitive Type Streams in Java
One of the important class with in Java Stream API is Collectors class that is an implementation
of Collector interface, this class implements various useful reduction operations.
Read more about Collectors class in this post- Collectors Class And collect() Method in Java
Creating a Stream
With in the Java Stream API there are number of ways to obtain a stream.
1. Stream from Collection- Stream can be created from any type of Collection via the stream() and parallelStream() methods.
List<Integer> myList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); Stream<Integer> myStream = myList.stream();
2. Stream from an array- Stream can be obtained from an array via Arrays.stream(Object[]);
String[] array = {"a", "b", "c"};
Stream<String> stream = Arrays.stream(array);
3. Using Stream.of() method- Stream can also be created using static factory method Stream.of(Object[])
Stream<String> stream = Stream.of("a", "b", "c");
4. Using range and iterate methods- Using range method you can get a primitive stream.
IntStream stream = IntStream.range(1, 10);
Same thing (getting stream of integers 1-9) can be achieved by using the iterate method-
Stream<Integer> stream = Stream.iterate(1, n-> n < 10, n->n+1);
5. Creating empty stream- You can create an empty stream using empty method.
Stream<Integer> stream = Stream.empty();
6. To get lines of a file as a stream you can use BufferedReader.lines() method.
Path path = Paths.get("D:\\KnpCode\\test.txt");
Stream<String> lines = Files.newBufferedReader(path).lines();
Types of Stream operations
Stream operations are divided into two types-
- intermediate operations
- terminal operations
Intermediate operations in Java Streams
Intermediate operations return a new stream. This new stream is a result of applying intermediate operation on the source stream. Intermediate operations are always lazy and these operations are executed only when a terminal operation is executed.
For example executing an intermediate operation such as filter() does not actually perform any filtering, but instead creates a new stream that, when traversed, contains the elements of the initial stream that match the given predicate. Traversal of the pipeline source does not begin until the terminal operation of the pipeline is executed.
Intermediate operations are further divided into two categories-
- Stateless operations- Stateless operations, such as filter and map, retain no state from previously seen element when processing a new element, each element can be processed independently of operations on other elements.
- Stateful operations- Stateful operations, such as distinct and sorted, may incorporate state from previously seen elements when processing new elements.
Some of the examples of intermediate operations in Java Stream API are filter, map, flatMap, distinct, sorted, limit.
Examples of intermediate stream operations
1. filter()- In filter method Predicate is passed as an argument and method returns a stream consisting of the elements of this stream that match the given predicate. Predicate is a functional interface which can be implemented as a lambda expression.
From an ArrayList you want to filter elements less than 5.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3); Stream<Integer> myStream = myList.stream().filter(n -> n > 5); myStream.forEach(System.out::println);Output
11 9 98 17 8
2. map()- Using map method you can map (convert) each element in the stream to another object. Method returns a stream consisting of the results of applying the given function to the elements of this stream.
If you have a List of Strings and you want to apply upper case function to each string.
List<String> myList = Arrays.asList("rose", "lotus", "lily", "orchid");
myList.stream().map(s -> s.toUpperCase()).forEach(System.out::println);
Output
ROSE LOTUS LILY ORCHID
3. flatMap()- The flatMap() operation applies a one-to-many transformation to the elements of the stream and also flattens the resulting structure into a new stream. If you have an object with many nested objects flatMap() operation brings all the nested level objects to the same level by flattening the structure.
If you want to produce a stream of the words contained in the Strings in the array.
Stream<String> lineStream = Arrays.stream(lines);
Stream<String> str = lineStream.flatMap(line -> Stream.of(line.split(" +")));
4. distinct()- Returns a stream consisting of the distinct elements of this stream.
distinct() method of the Java Stream API provides a best option to remove duplicates from a List.
List<Integer> ListWithDuplicates = Arrays.asList(7, 8, 9, 7, 4, 2, 4, 1);
List<Integer> uniqueElementList = ListWithDuplicates.stream().distinct().collect(Collectors.toList());
System.out.println("List after removing duplicates : " + uniqueElementList);
Output
List after removing duplicates : [7, 8, 9, 4, 2, 1]
5. sorted()- Returns a stream consisting of the elements of this stream, sorted according to natural order. This is a stateful intermediate operation.
List<Integer> myList = Arrays.asList(7, 8, 9, 7, 4, 2, 4, 1); myList.stream().sorted().forEach(System.out::println);Output
1 2 4 4 7 7 8 9
6. limit()- Using limit() method you can limit the number of elements in a Stream to the size passed with limit() method.
List<Integer> myList = Arrays.asList(7, 8, 9, 7, 4, 2, 4, 1); myList.stream().limit(3).forEach(System.out::println);Output
7 8 9
Terminal operations in Java Streams
Once the terminal operation is performed in a Stream, the stream pipeline is considered consumed. Same stream can no longer be used; if you need to traverse the same data source again, you must return to the data source to get a new stream.
Terminal operations are eager (except iterator() and spliterator() methods) , completing their traversal of the data source and processing of the pipeline before returning.
Some of the examples of terminal operations in Java Stream API are forEach, reduce, collect, min, max, count, findFirst.
Examples of Terminal stream operations
1. forEach()- In the forEach method a Consumer is passed as an argument and this Consumer action is performed on each element of this stream.
List<String> myList = Arrays.asList("rose", "lotus", "lily", "orchid");
myList.stream().forEach(System.out::println);
Output
rose lotus lily orchid
2. reduce()- Reduce operation reduce the stream to a single non-stream value. This method returns an Optional describing the result of the reduction.
You can find max element in a Collection using reduce method.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
Optional<Integer> max = myList.stream().reduce((n1, n2) -> n1 > n2 ? n1:n2);
if(max.isPresent()){
System.out.println("Max element in the List " + max.get());
}
Output
Max element in the List 98
3. collect()- Java Stream API’s collect() method is used to collect the Stream elements in a mutable container like a List, StringBuilder.
In the example list is filtered to filter out all the elements less than 5 and the stream elements are collected in a TreeSet which sorts the resulting elements.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
Set<Integer> sortedSet = myList.stream().filter(n->n>5).collect(Collectors.toCollection((TreeSet::new)));
System.out.println("Sorted set- " + sortedSet);
Output
Sorted set- [8, 9, 11, 17, 98]
4. min()- Returns the minimum element of this stream according to the provided Comparator. This method returns an Optional describing the minimum element of this stream.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
Optional<Integer> min = myList.stream().min(Integer::compare);
if(min.isPresent()){
System.out.println("Minimum element in the List " + min.get());
}
Output
Minimum element in the List 0
5. max()- Returns the maximum element of this stream according to the provided Comparator. This method returns an Optional describing the maximum element of this stream.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
Optional<Integer> max = myList.stream().max(Integer::compare);
if(max.isPresent()){
System.out.println("Maximum element in the List " + max.get());
}
Output
Maximum element in the List 98
6. count()- Returns the count of elements in this stream.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
long count = myList.stream().count();
System.out.println("Count of elements in the list- " + count);
Output
Count of elements in the list- 10
7. findFirst()- Java Stream API's findFirst() method returns an Optional describing the first element of this stream, or an empty Optional if the stream is empty.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3);
Optional<Integer> value = myList.stream().findFirst();
if(value.isPresent()){
System.out.println("First Element- " + value.get());
}
Output
First Element- 11
Stream pipeline in Java Stream
A data source (such as a Collection, an array, a generator function, or an I/O channel) followed by zero or more intermediate operations and a terminal operation together form a stream pipeline.
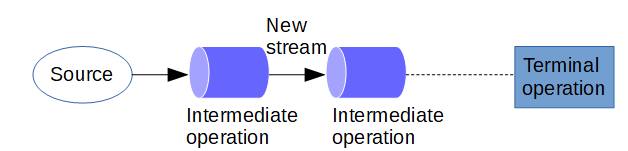
In the following example stream source is an ArrayList. First intermediate operation is a map operation which adds 10 to each element in the Stream, in another operation elements are sorted. Then the elements are displayed using forEach terminal operation, at this point the stream is consumed.
List<Integer> myList = Arrays.asList(11, 1, 9, 4, 98, 0, 17, 8, 2, 3); myList.stream().map(n -> n + 10).sorted().forEach(System.out::println);
Collection Vs Stream API
Streams differ from collections on several points-
- No Storage- Unlike Collections a stream is not a data structure that stores elements. In a stream, elements from a data source are moved through a pipeline while going through computational operations at each intermediate step.
- Functional in nature- Java Stream API is functional in nature bringing functional approach to processing collections of objects. An operation on a stream produces a result, but does not modify its source. For example, filtering a Stream obtained from a collection produces a new Stream without the filtered elements, rather than removing elements from the source collection.
- Lazy invocation- Intermediate operations in the Java Stream API are always lazy providing opportunities for optimization.
- Possibly unbounded- While collections have a finite size, streams need not. Short-circuiting operations such as limit(n) or findFirst() can allow computations on infinite streams to complete in finite time.
- Streams are Consumable- The elements of a stream are only visited once during the life of a stream, once a terminal operation is encountered with in a Stream pipeline, stream is considered consumed. After a stream is consumed a new stream must be generated to revisit the same elements of the source.
That's all for the topic Java Stream API With Examples. If something is missing or you have something to share about the topic please write a comment.
You may also like
- Java Parallel Streams With Examples
- Java Stream - Reduction Operations And Reduce Method
- Java Stream Collectors.partitioningBy() Examples
- java.time.Period Class With Examples
- Java Static Import With Examples
- ReentrantLock in Java With Examples
- Stable and Unstable Sorting Algorithms
- Encapsulation in Python With Examples
- Injecting List, Set or Map in Spring
- Spring Boot Microservices Example


